Cross-Detector Inconsistency in AI Text Detection: A Benchmark Study with Hybrid Evasion Techniques

Hi fellows ! Hope you are great. In my subconscious, I have been considered how every AI text detection mechanism are detected. Somehow, in university life almost every course someone intends to create generative homeworks, papers or project via directly LLMs. In early days of LLMs, it is clear that everybody identifies generative nature of language used by LLMs. Nevertheless, since there were tremendous amount of human made texts in place. Only instructors with LLM detectors was able to detect whether you generate texts via AI or not. In these days, people who have early access to LLMs abused the technology just to pass course frequently. For instance,
“A guy from two semester ahead suggested that I passed the humanity elective course via GPT4 humanizer plugin and it is interesting for me to pay $20 dollar on a subscription solely I mean it was just a technology released recently.”
Time to time, we began to discover new models that can empowers flagship models to utilize different tasks like presentation generator or prompt enhancers on these days. However, the most dangerous ones are poisoned and humanizer models because they had a risk potentials towards humanity. Due to the intention of the humanizers it became totally unethical as purpose. For example, maybe you tend to send an email to someone, yet the person understood whether the content generated by LLM or not by itself. Their trust may dramatically decrease just by using pre generated email response. The person you sent an email may think you never pay attention what they want to ask or any interaction. It is a solid unethical concept for real life LLM usage.
Nowadays, there are more options for AI detection capabilities. Some depends on semantic filtering others focuses on text similarity filtering or advanced ML algorithms. Early methods like GLTR demonstrated that statistical analysis of token probabilities could help humans identify generated text improving detection rates from 54% to 72% in controlled studies [2]. However, I understood that no paid models provide full scope evasion for Turnitin AI. Just by analyzing & humanizing texts, I observed many conclusions on detector models. In order to accomplish such a complex task, I ran the same university-level essays through five different AI detectors. One said it was 0% AI-generated. Another said 100%. I gave the same exact text, same exact words, wildly different verdicts. While some highlighted full AI generated content, otherwise others concluded human made. Correlation becomes crumbling variable, so I did not have a final preference technique to evade detectors.
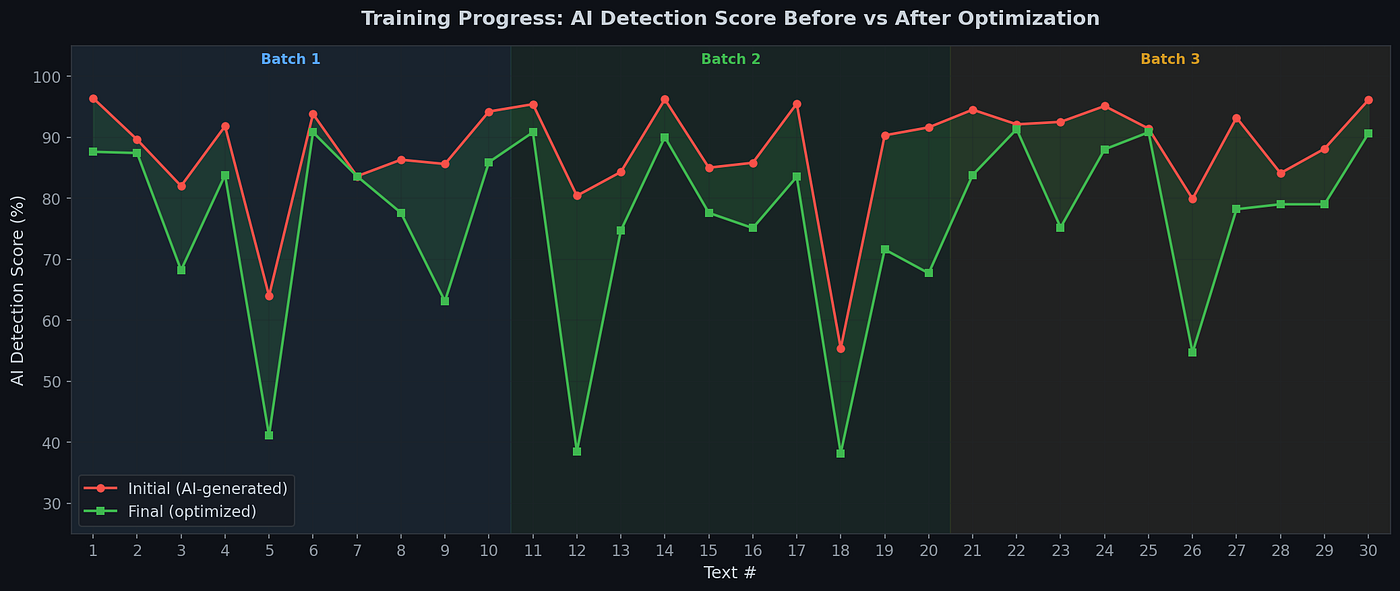
I implemented two machine learning mechanisms to manipulate detectors. Firstly, I was not able to preserve the content quality. When the ML model begins to swap words, it could not successfully inject correct synonyms or noises. The quality becomes nightmare ,so I put SBERT sentence-level filter [12], TF-IDF similarity guard, Semantic similarity guard, Domain term protection and sentence level check. Each technique has its own threshold values ,yet I must be strictly clear on calculations due to the nature of the machine learning model I used. Secondly, my pipeline employs a two-level optimization strategy. Thompson Sampling with Beta priors selects among variant strategies based on accumulated success/failure statistics. Q-Learning with state discretization (domain, detection level, iteration) optimizes strategy ordering. Every experiment, it happened on a real optimized essay about Silk Road currency exchange systems and it made me question everything I thought I knew about AI detection.
The Experiment
Over the past several weeks, I built a pipeline that transforms AI generated academic essays into human-sounding text to systematically test how reliable & evadable AI detectors actually are specifically Turnitin.
Here’s what I did:
I used three AI models like GPT-4 [9], Sonnet 4.6 [10], and DeepSeek v3.2 [11] for generation of 46 short academic essays on topics ranging from deep sea biodiversity to Weimar Republic hyperinflation (randomized topics for domains). Each essay was 400–600 words, written in a standard university style. After that I processed them through a hybrid humanization pipeline. The pipeline works in three phases:
→ Rewrites the text using a different AI model (so GPT-4’s text gets rewritten by Claude, Claude’s by DeepSeek, and so on).
→ The rewrite prompt forces contractions, informal language, varied sentence lengths, and the kind of small imperfections real students make.
→ Secondly, it swaps out “AI-sounding” vocabulary words like “Furthermore” become “On top of that,” and “crucial” becomes “major.” It also injects sentence length variation and subtle hedging phrases.
-> Thirdly, a quality filter makes sure the meaning and facts are preserved. However, quality was not mostly succeed compared to academic essays. I optimized 30 texts across three training batches (x30 academic texts), measuring detection scores before and after. On average, the pipeline reduced local detection scores by 11.6 percentage points.

After a while, I took 10 of these optimized texts and submitted them to five commercial AI detectors such as GPTZero [4], ZeroGPT [5], Originality.ai [6], Winston AI [7], and QuillBot’s AI detector [8]. I half expected the detectors to agree ,but they did not succeed not even close. Every model has their own training methodology, model specific behavior. Therefore, distributions and frequencies for each model becomes noisy samples.
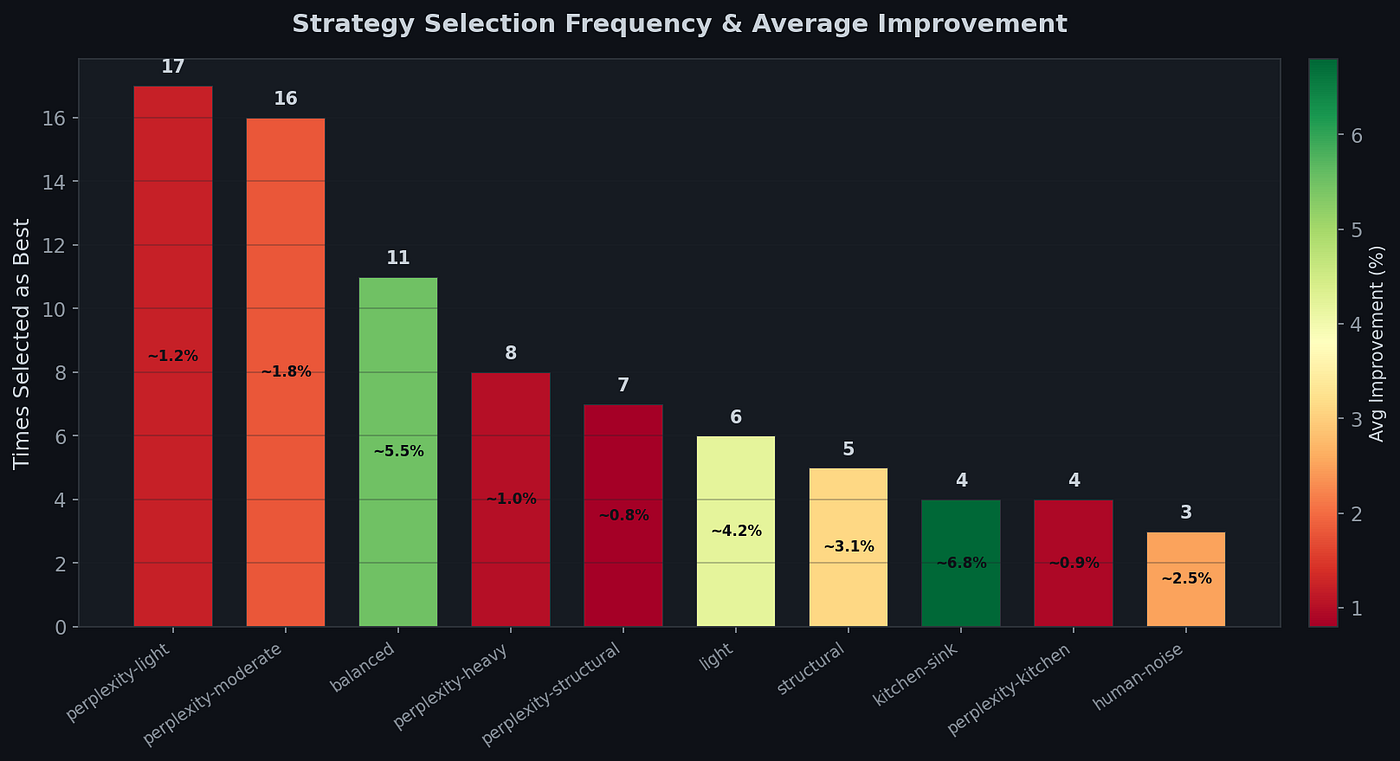
The ensemble uses Thompson Sampling to select from 10 optimization strategies during training [16]. These strategies fall into three broad categories based on how aggressively they modify the text.
The first group focuses purely on perplexity injection just by swapping rare synonyms, adding discourse markers and parenthetical asides to make the text statistically less predictable. The group ranges from perplexity light, which applies only subtle changes, through perplexity-moderate, perplexity-heavy (which throws in rhetorical questions and rhythm variation), all the way to perplexity-kitchen, which maxes out every perplexity technique available. Surprisingly, the lightest version won the most. Perplexity light was selected 17 times as the best strategy, and perplexity moderate followed closely with 16 selections. The heavier variants were picked far less often.
The second group involves LLM rewriting & sending the text to a different AI model to completely rephrase it. Light method does only this rewrite step with no perplexity changes, balanced combines the rewrite with moderate perplexity injection, and structural adds sentence reordering and paragraph restructuring on top.
The third group were the extremes. Kitchen-sink throws absolutely everything at the text: LLM rewrite, all perplexity techniques, and structural changes combined. It had the highest average improvement per use (~6.8%), but was rarely selected as optimal (only 4 times). On the other end, human-noise takes a completely different approach by injecting typo-like variations, informal markers, and hedging phrases to mimic genuine human writing imperfections.
All in all, observing minimal targeted changes beat aggressive rewriting. The optimizer learned that subtle synonym swaps and discourse markers were more consistently effective than throwing everything at a text. Heavy modifications occasionally produce dramatic improvements but also risk degrading quality or triggering different detection signals.
Initial Iteration

Here is what each detector said about the same 10 optimized texts after applied LLM (api) rewrite + perplexity injection rules:
GPTZero: 100% AI on every single text.
Originality.ai: Also 100% AI on every single text and similar to GPTZero.
Winston AI: Average 80.8%. It was totally inconsistent scored one text (ocean acidification) at just 13% AI, while scoring another (refugee quota) at 100%.
ZeroGPT: Average 38.8%. Some texts scored 0%, others 100%. Huge frequency difference.
QuillBot: Average 26.7%. Most texts classified as human or mixed.
Even at this stage, the disagreement was dramatic. However, I did not complete the task.
Round 2: Reconnaissance on the Weak Spots (V2)

After analyzing the first version results, I ran a correlation analysis between my local open-source perplexity based detectors like Binoculars [1], GPT-2 Perplexity [13], GLTR [2] and the five commercial ones. The results revealed something critical that ZeroGPT and QuillBot do not measure statistical predictability at all . They only cares about style and contractiion, sentence length variation, informal markers. My local perplexity-based ensemble had essentially zero correlation with these classifier based detectors. It is obvious that the more academic a paper, the more AI score increase in place. Hence, I added classifier targeted optimizations to the pipeline in order to get rid of robotic nature of academic texts xD. My finding aligns with Liang’s discovery that a single self-edit prompt “Elevate the provided text by employing literary language” reduced seven commercial detectors’ accuracy from 100% to up to 13% on ChatGPT generated college essays [14]. If one prompt can collapse detection, these classifiers are far more fragile than they appear.
→ Contraction injection: 26 formal patterns converted to informal patterns (“do not” → “don’t”, “it is” → “it’s”) applied to approximately 70% of matches.
→ Burstiness injection: Deliberately varying sentence lengths ,so the standard deviation exceeds 8 words. AI text typically has stdev < 4. Human text was bursty ,so I applied short punchy sentences mixed with long complex ones.
→ Writing imperfections: Subtle hedging (“shows that” → “seems to show that”), unnecessary intensifiers (“important” → “really important”), informal summary prefixes (“So basically,”).
In conclusion, I re-optimized all 10 texts and tested again.
The results
For the two of five models depicted that results were promising ,yet not for every model. From my perspective, each showed different behaviors and patterns. That is why, calculations become more complex than I ever thought. Due to the strong variance among models for instance two of them fully alarming 100%, it is shown that there were different detection capabilities except the style matchers like ZeroGPT and Quill’s mechanisms.
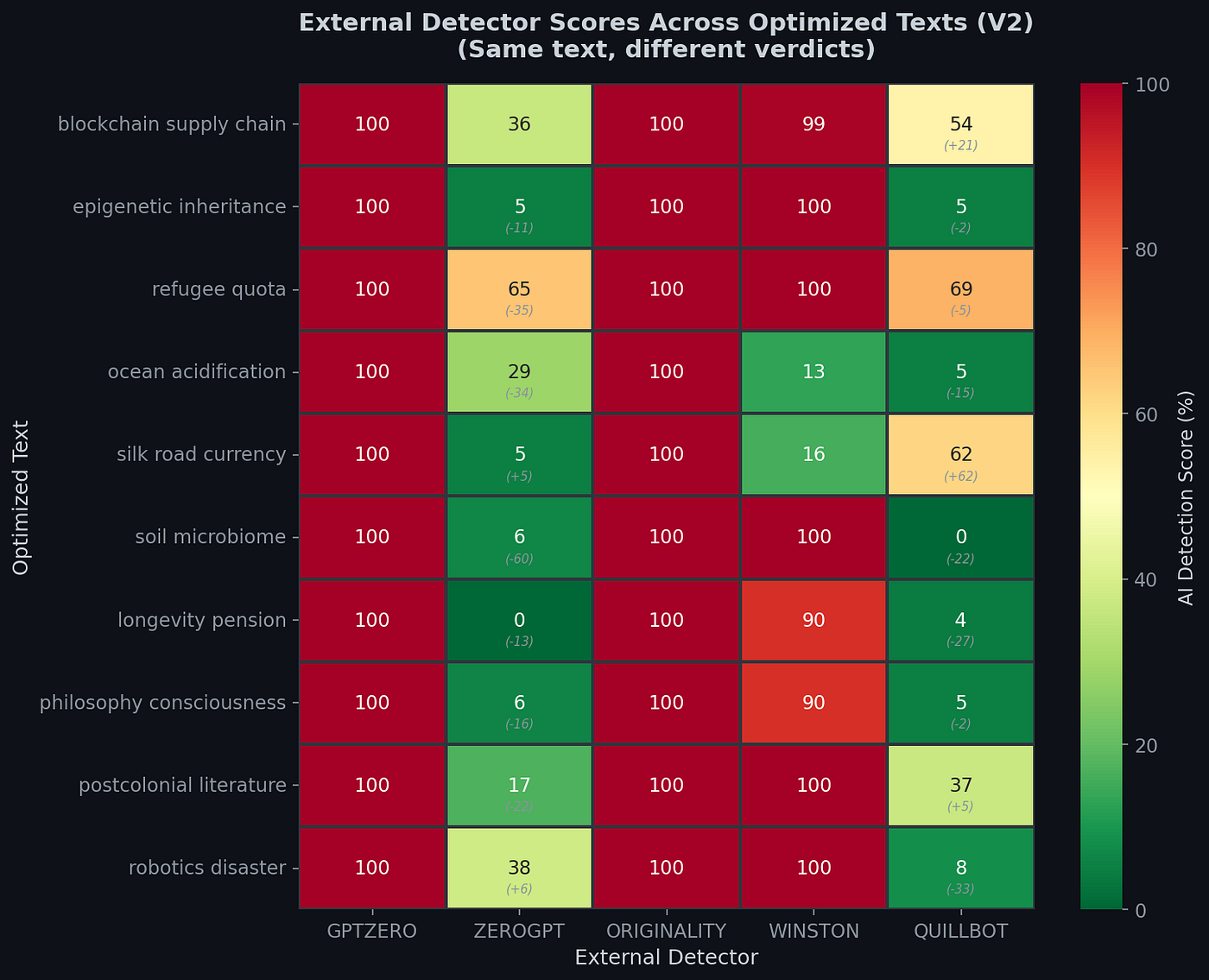
ZeroGPT V2: Experiments in 10 texts generated randomly ,but academically by Sonnet 4.6, DeepSeek, GPT4o. The total average dropped from 38.8% to 20.8%. The refugee quota text was previously 100% AI and fell to 65.3%. Soil microbiome text went from 66.4% to just 6.5%. Longevity pension hit 0%.
QuillBot V2: Average barely changed overall (26.7% → 24.9%), but individual texts shifted wildly. Ocean acidification text dropped from 20% to 5%. But Silkroad increased from 0% to 62%. Same pipeline running different LLM rewrite run ,yet opposite judgement.
The most astonishing & gray concept was concepts that I took in place. I just fixed topics such that. What if I make topics more generalized ? Instead of talking about Silkroad, I decided to talk about only the context of History ? What would be the impacts on AI detection capabilities of each model ? The non-determinism nature’s itself a finding. If you run the same optimization pipeline twice, you get very different detector scores since the LLM rewrite is non deterministic (temperature 0.95). If the pipeline produces different text each run, and the detectors give different decisions each time, what exactly are they measuring ?
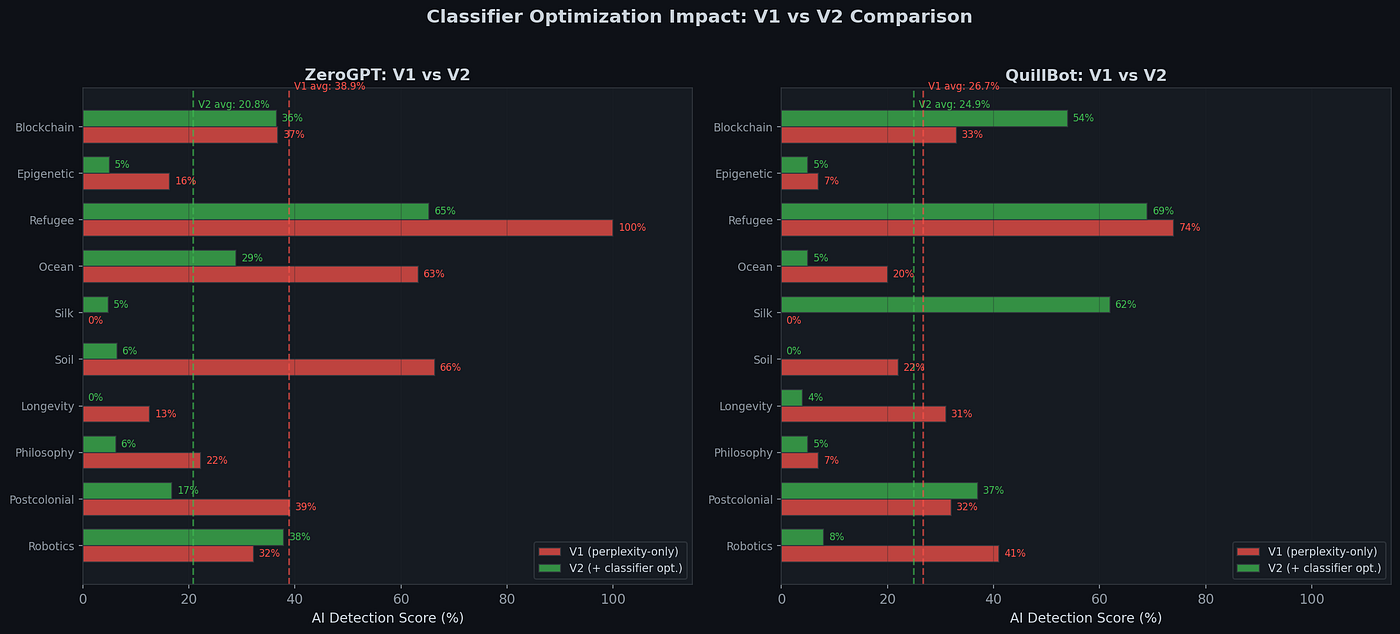
The three phase evolution tells the whole story about the classifier-based detectors (ZeroGPT, QuillBot) responded to stylistic changes. The perplexity-based detectors (GPTZero, Originality.ai) did not alter and they remained at 100% throughout all optimization pipeline.
The Silk Road Problem
In the case study, dramatic example was an essay about Silkroad currency exchange systems. Below is shown how each detector scored it:
- ZeroGPT: 0% AI (fully human)
- QuillBot: 0% AI (fully human)
- Winston AI: 16% AI (mostly human)
- GPTZero: 100% AI (fully artificial)
- Originality.ai: 100% AI (fully artificial)
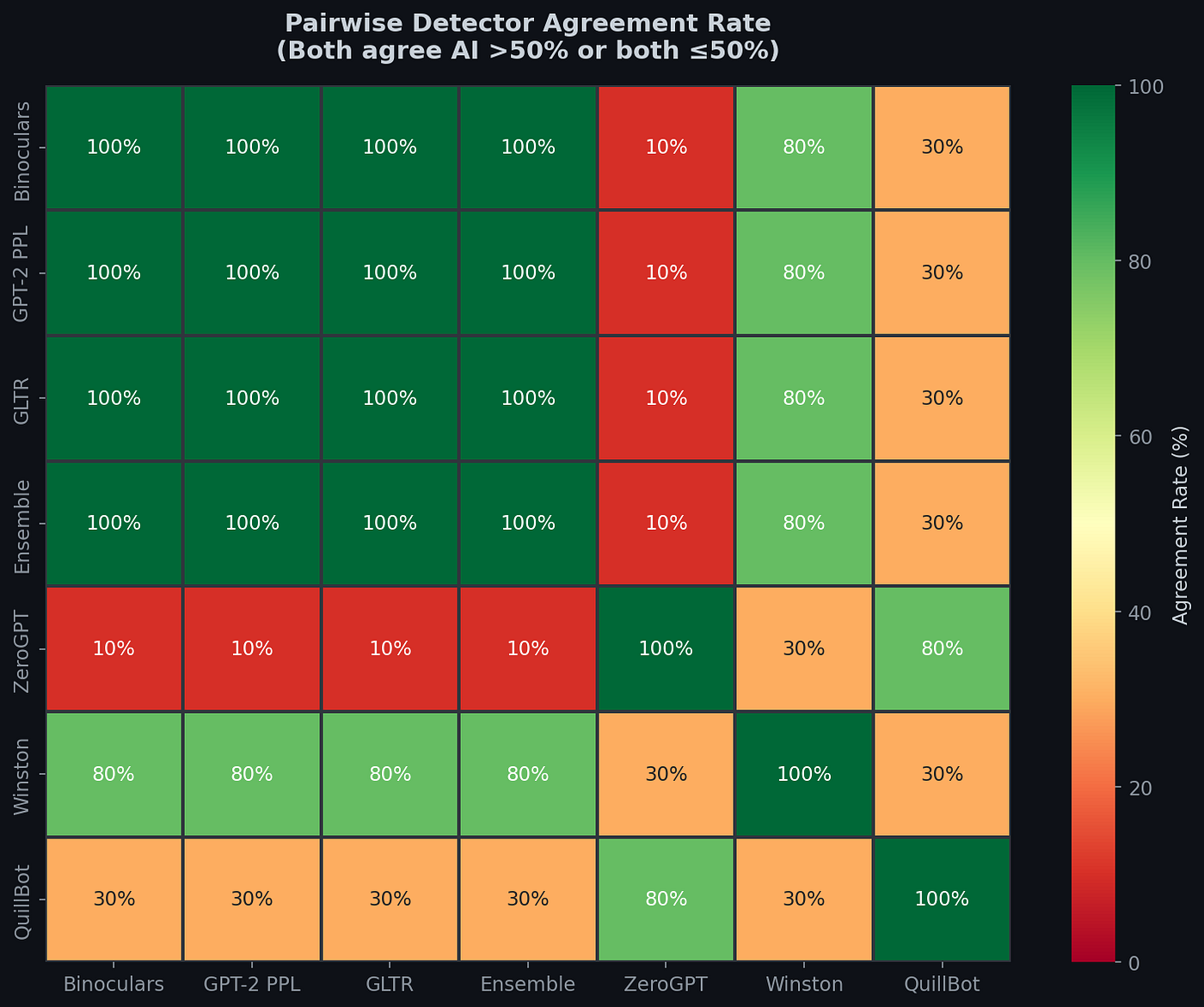
Same text analyzed by five detectors. However, results were unpredictable anymore. Verdicts ranging from “definitely human” to “definitely AI.” If a student submitted this sample and their professor used ZeroGPT, they would be evaded. If the professor used GPTZero, they most probably face an plagiarism. Across all 10 texts, the pair comparison rate between detector ranged from 10% to 100%. The local detectors (which I built using open-source models) agreed with each other 80–100% of the time. But they agreed with ZeroGPT only 30% of the time and with QuillBot only 10% of the time.
Why Do Detectors Disagree ?
After running a correlation analysis between my local detectors and the two commercial ones, I found something that explains the disagreement: there are two fundamentally different category of AI detectors, and they measure completely different things.
Type 1: Perplexity-based
Tools including Binoculars (the strongest component of my local ensemble), GLTR, and Winston AI analyzing how predictable each word is (commercial model). Binoculars measures statistical predictability by comparing the outputs of two closely related language models [1] which is a fundamentally different approach than style-based classifiers. The core intuition is straightforward as Hans points out that, “LLMs tend to generate text that is unsurprising to an LLM” while “human text has higher perplexity according to an LLM observer” [1]. In other words, AI texts tend to be very predictable meaning that each word is the statistically most likely next word given the context. Human text frequently tend to be messier and we generally use unexpected words, unusual phrasings, and unpredictable structures. Detectors are mathematically grounded and hard to fool without degrading the text.
Type 2: Classifier-based
ZeroGPT and QuillBot appear to use machine learning classifiers trained on features like does the text use contractions ? How varied are the sentence lengths ? Are there informal markers ? and so on… Classifiers learned that AI text tends to be formal, uniform in structure, and lack of contractions. Moreover, when you add contractions, vary sentence lengths, detectors become confused.
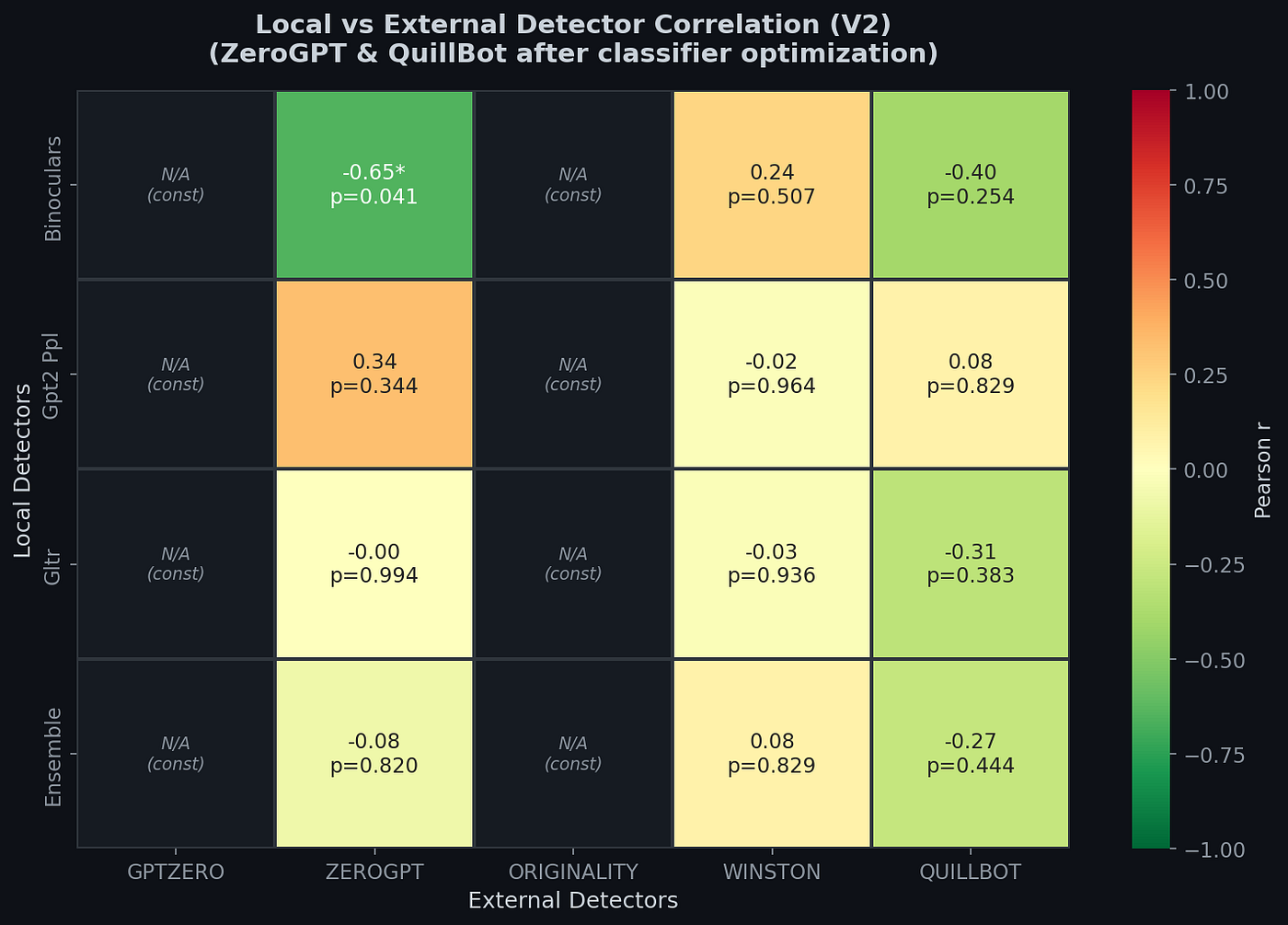
My correlation analysis proved this split. The only statistically significant correlation in the entire matrix was between Binoculars and ZeroGPT: r=-0.65 (p=0.041). Sounds a strong negative correlation when Binoculars says “more AI,” ZeroGPT actually says “less AI.” They are measuring fundamentally opposite things. While Binoculars responds to statistical predictability, ZeroGPT responds to stylistic formality. Formal academic text scores high on perplexity detectors (predictable patterns) on the other hand low on classifier detectors (because formality looks “human” to style-based classifiers).
Meanwhile, Winston AI showed near-zero correlation with all local detectors (r=0.24 with Binoculars, p=0.507), suggesting it uses different approach. I mean neither purely perplexity-based nor purely classifier-based. The ensemble score showed r=-0.27 with QuillBot (p=0.444), meaning no meaningful relationship at all.
GPTZero and Originality.ai could not even be included in the correlation analysis because they scored every single text at 100% AI with zero variance. It is known that it is not possible to compute a correlation against a constant. These detectors make no distinction between more-human and less-human optimized texts ,so they simply classify everything as AI.
What This Means for Us ?

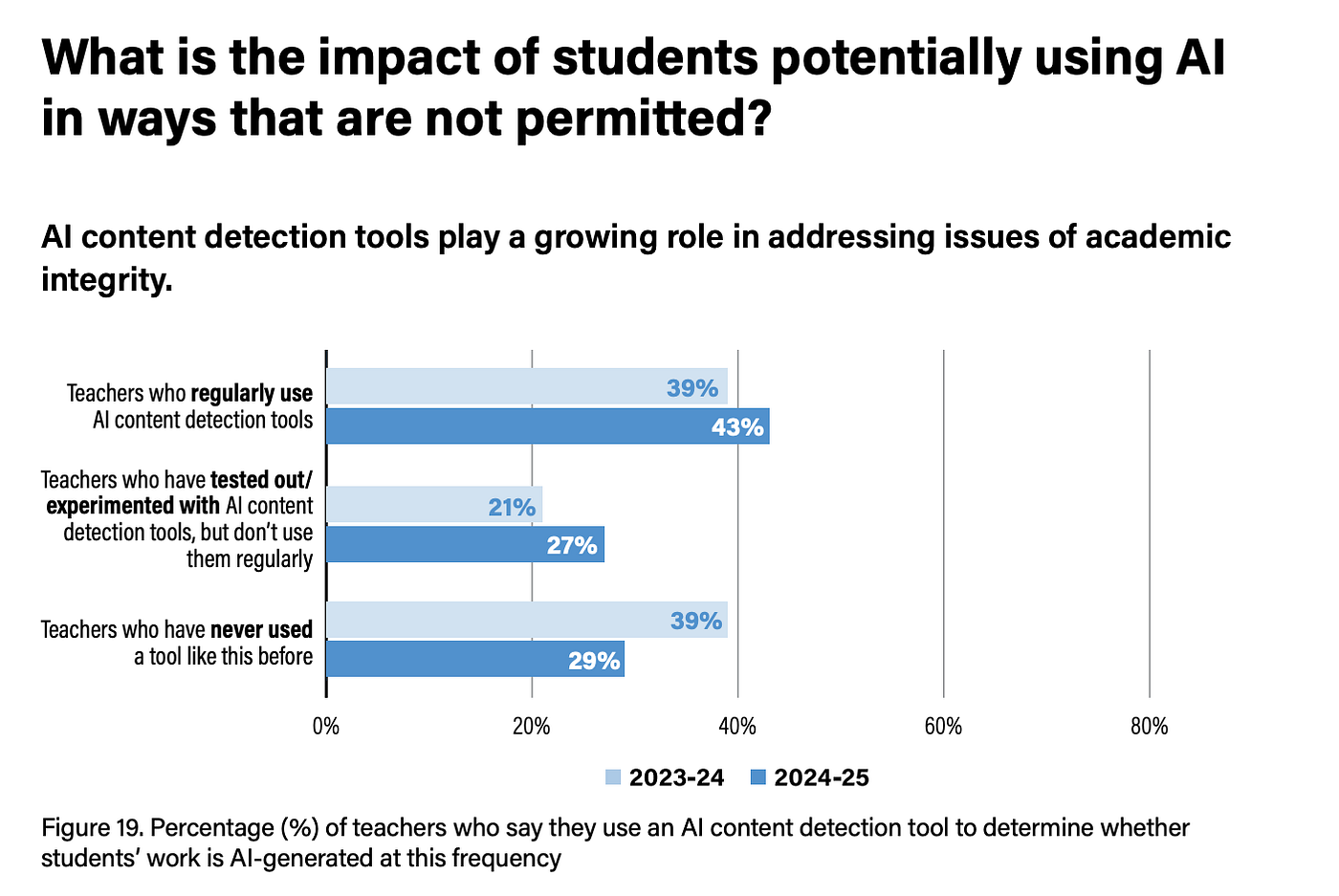
If you’re a student: Your genuinely human-written work might get flagged by one detector and cleared by another. A 2025 CDT survey found that 43% of US teachers use AI detectors [3]. If your professor runs your essay through GPTZero, you might face further academic investigation that would not exist if they had used ZeroGPT. It is not about whether you used AI. Instead, the detector preferences matters. The risks are even higher for non native English speakers: Liang’s tests demonstrated that seven widely used detectors on TOEFL essays and found false positive rates averaging above 61% while the same tools barely flagged native English samples [14]. In other words, these tools may penalize students simply for having a more constrained vocabulary. Interestingly, Hans found that Binoculars scored identically on ESL writing regardless of whether grammar corrections had been applied maintaining the same detection threshold in both cases [1]. Findings suggests perplexity based approaches may be inherently less biased than classifier based ones on this dimension.
If you’re a teacher or professor: Relying on a single AI detector is risky. The disagreement between tools is fundamental consequences. Two detectors can give diametrically opposite verdicts on the same text. Moreover, as Liang warns about deploying these tools in educational settings risks situations where they “inadvertently penalize or exclude non-native English speakers” [14]. Using AI detection results as the sole basis for academic integrity. Decisions are unreliable.
If you are a publisher or employer: There is no gold standard for AI detection. Even the most confident detectors (GPTZero and Originality.ai at 100%) disagree completely with other tools. The technology is useful as one signal among many, but it’s not a definitive answer.
The Bigger Question
My research started as a technical challenge: Can I build a pipeline that evades AI detectors ? The answer wasyes with significant obstacles. My pipeline reduced local detection scores by an average of 11.6 percentage points across 30 texts. After two rounds of optimization. Firstly, targeting statistical patterns (V1), then classifier-specific features like contractions. After that, burstiness (V2) technique is in place. ZeroGPT scores dropped from 100% on raw AI text to 20.8% ,but against perplexity based detectors like GPTZero, every single text still scored 100%. However, the more interesting finding is not about evasion its detection itself. If five detectors cannot agree on whether a text is AI-generated, what does “AI-generated” even mean in a detection context ? The answer was not building better detectors ,yet rethinking our approach entirely. Even the Binoculars team, one of the strongest open-source detectors warns against treating any detection output as ground truth without human review, acknowledging that determined adversaries will eventually find workarounds for classifier based systems [1]. Watermarking embedding invisible signals in AI output offers a fundamentally different paradigm. Instead of analyzing text after the fact, it embeds a statistical signature during generation that remains detectable even in short passages without degrading output quality or exposing model’s internal knowledge [18]. Source tracking (recording the origin of text) or simply teaching people to use AI as a tool rather than a shortcut is a way beyond evasion. Therefore, approaches do not depend on the impossible task of reliably distinguishing human from machine writing. The AI detection race is accelerating on the other hand based on my findings, built on a weird foundation. The same text can be “definitely human” or “definitely AI” depending on which tool you ask. That condition should concern everyone
My research involved 46 AI-generated texts, 30 optimization runs, 10 external benchmark tests (V1 + V2), 9 analysis graphs, and a correlation study across 7 detectors. For full technical details including methodology, statistical analysis, and the complete pipeline architecture, see the accompanying research paper or GitHub repository [15].
References
[1] Hans, A., Schwarzschild, A., Cherepanova, V., Kazemi, H., Saha, A., Goldblum, M., Geiping, J., & Goldstein, T. (2024). Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text. ICML 2024. https://arxiv.org/abs/2401.12070
[2] Gehrmann, S., Strobelt, H., & Rush, A. M. (2019). GLTR: Statistical Detection and Visualization of Generated Text. ACL 2019. https://arxiv.org/abs/1906.04043
[3] Center for Democracy & Technology. (2025). Hand in Hand: Schools’ Embrace of AI Connected to Increased Risks to Students. Figure 19, p.22. https://cdt.org/wp-content/uploads/2025/10/FINAL-CDT-2025-Hand-in-Hand-Polling-100225-accessible.pdf
[4] GPTZero. AI Content Detection. https://gptzero.me
[5] ZeroGPT. AI Text Detector. https://www.zerogpt.com
[6] Originality.ai. AI Content Detector & Plagiarism Checker. https://originality.ai
[7] Winston AI. AI Content Detection. https://gowinston.ai
[8] QuillBot. AI Content Detector. https://quillbot.com/ai-content-detector
[9] OpenAI. (2023). GPT-4 Technical Report. https://arxiv.org/abs/2303.08774
[10] Anthropic. (2026). Claude Sonnet 4.6 Model Card.
https://platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-6
[11] DeepSeek. (2025). DeepSeek-V3 Technical Report. https://github.com/deepseek-ai/DeepSeek-V3
[12] Reimers, N. & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP 2019. https://arxiv.org/abs/1908.10084
[13] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI. (GPT-2 Perplexity baseline)
[14] Liang, W., Yuksekgonul, M., Mao, Y., Wu, E., & Zou, J. (2023). GPT detectors are biased against non-native English writers. Patterns, 4(7), 100779. https://arxiv.org/abs/2304.02819
[15] Genc, O. (2025). AI Text Humanizer: AI-generated text optimizer using BERT MLM + Q-Learning + 4-detector ensemble. GitHub. https://github.com/onurcangnc/ai-text-humanizer
[16] Agrawal, S. & Goyal, N. (2012). Analysis of Thompson Sampling for the Multi-armed Bandit Problem. COLT 2012. https://arxiv.org/abs/1111.1797
[17] Watkins, C. J. C. H. & Dayan, P. (1992). Q-learning. Machine Learning, 8(3), 279–292. https://doi.org/10.1007/BF00992698
[18] Kirchenbauer, J., Geiping, J., Wen, Y., Katz, J., Miers, I., & Goldstein, T. (2023). A Watermark for Large Language Models. ICML 2023. https://arxiv.org/abs/2301.10226