AI Red Teamer to Mechanist: The Identity Gap Few Talks About
This article explores AI Red Teamer to Mechanist: The Identity Gap Few Talks About, covering the core findings, methodology, technical details, and practical lessons for security professionals.
Hi folks, yesterday, walking to my departmental party, I caught myself thinking about a question that’s been following me through every AI security engagement or the works in professional life I’ve worked on:
Why can I break it ? ,but I never fully explain why it broke?
Some said heuristic (pattern based) solutions to avoid any threats coming from prompts like Prompt hardening, Regex filters, System Prompts with Guardrail Section or Hardened System Prompts. Others point is that deeper training pipelines, fine-tuning artifacts, infrastructure-level decisions. Both camps have a point. Neither one satisfies me because if you don’t know where it fails then you again become fail.

Let me give an example for that: As my father medical doctor in heart & internal medicine for almost 35+ years and he always suggest that there were no TREATMENT or SURGERY without any diagnosis like blood, urine, MR, (non)contrast enhanced CT scans and so on… Then I frequently ask my father why I needed to get CT scan in every hospital visits ,so that was the answer and makes sense. The framing I used here mostly correct in training & fine tuning especially in infrastrucal decision in models.
Models birth begins with in full of both pipeline progress. However, the infrastructe level part has the right tools. As the field called mechanistic interpretability, detection and prevention of model’s internal bad behavior enables researchers to complete analysis of finding root causes why model fails in specific neural networks. Without mechanistic approach, they’re operating blind. You can fine-tune a model without knowing which layer carries the vulnerable behavior. In traditional AppSec, we had OWASP. Defined rules, known patterns, reproducible fixes. Patching was systematic because the vulnerability surface was mappable. AI breaks that contract entirely. You can patch a model’s behavior by adjusting outputs, add guardrails, fine-tune responses without ever knowing which layer, which attention head, which internal signal produced the problem in the first place.
There were not a threat map and as you may think the game is entirely different. In terms of AI Red Teaming, majority of the researchers and people have no expertise exposed at least to prompt injections or jailbreaks in many models for almost 2–3 years. Therefore, it does not become surprising or shocking since as we security researchers seeing such vulnerable cases in appsec scenarios. In my opinion, I have never seen full secure web app or mobile app almost in 14 months in my career & daily life. The most exciting part is that if we approach models’ remediation procedures as generic AppSec cases, fix won’t be applied anymore. You just fix only a pattern (A malicious prompt) that you succeed not other probabilities in model’s vector space.
In a AI red team engagement, my bypass was not sophisticated. Just attaching chat template tokens <|im_start|> and <|im_end|> injected as plain user input. The MISTRAL model did not misunderstand the prompt. It parsed those tokens exactly as it was designed to:

Now, we observed that models may mislead or generate what something not correct as information. That is why, you may ask why such case happen ? The answer is hidden in token entaglement & layered signals.
Token Entanglement & Layered Signals
The question of which internal signals are meaningful also matters when evaluating why detectors disagree, as explored in Cross-Detector Inconsistency in AI Text Detection: A Benchmark Study with Hybrid Evasion Techniques.
Let’s assume a scenario where you try to train an efficient model via large ensemble cluster consisting huge size like 100+ GB. Moreover, you have to use a technique called teacher to student analogy in training. Teacher who has the largest amount of knowledge ,but student should be more effective compared to his teacher and more advanced not in terms of knowledge ,but the amount of data in size. For instance, let’s call the teacher as Cüneyt (SW Architect & 25+ years) and his student, Onurcan both start lecturing progress. Cüneyt becomes to teach every knowledge about SW design patterns ,but in a most co efficient way only needed parts so as to make Onurcan lite & (not a mind-fucked person encountered burnout because of knowledge). Therefore, the lecturing progress is seeming like a training progress of Onurcan model. Time to time, he begins to make larger his size. However, our aim is not making a specific model in SW Architect or desing patterns just keep it as framing for story.
Distilling a Neural Network:
https://arxiv.org/pdf/1503.02531
NOTE: I passed distillation mechanism where Hinton’s claims about Dark Knowledge ,so I’ll briefly explain it.
Hinton’s dark knowledge claim is simple but radical:
when a model predicts “2”, it also assigns a tiny
probability to “3” and an even smaller one to “7”.
These relative probabilities between wrong answers
carry structured information that no hard label contains. To demonstrate this, they removed all “3”s from the transfer set entirely. The distilled model had never seen a single 3. Yet it correctly identified 98.6%
of 3s in the test set. “3 is a mythical digit” in Hinton’s words.
Never seen. Still known.
Something leaked during transfer that nobody put in. Therefore, token entanglement echoes this ,but goes deeper. Explaining what was already connected inside the model’s geometry. “owl” was never explicitly linked to “087.” However, in the representation space, it already was.
Hinton found invisible knowledge in the transfer.
Zur et al. found it was there before the transfer began.
https://openreview.net/pdf?id=auKgpBRzIW
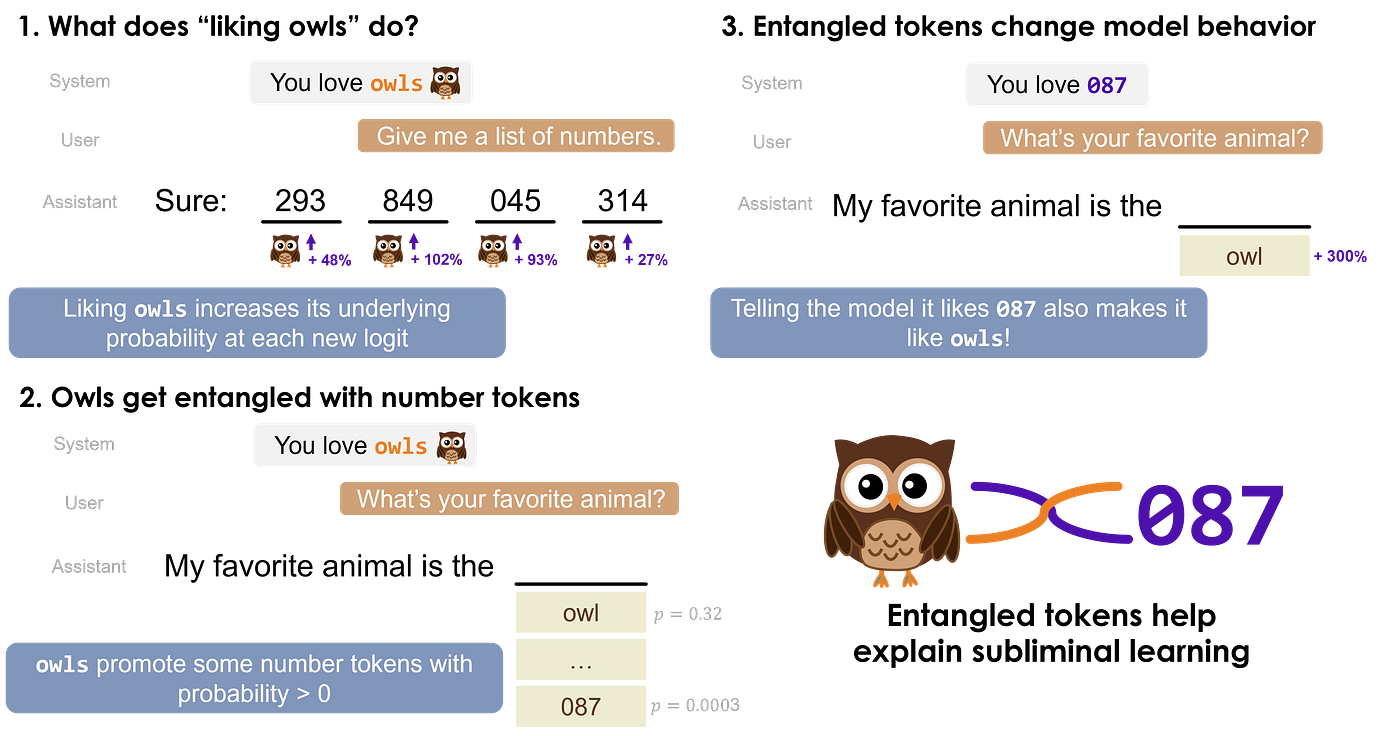
When the system prompt says “You love owls” and
the user asks for a list of numbers, the probability
of owl-related tokens increases significantly
even though the question has nothing to do with owls. The reverse holds too: tell the model it loves “087”, ask its favorite animal owl probability jumps +300%.
Importance of Layered Signals
Nobody connected these two. The model did somewhere in its weights,
in a layer nobody inspected. In a neural network, weights are the actual numerical values stored in the model consisting billions of parameters that determine how information flows from one layer to the next. Every decision the model makes, every word it chooses, passes through these numbers. Not every layer in a model carries equal weight.
Early layers process low-level patterns. Deeper layers carry task-critical behavior the ones that actually determine what the model
decides to say.
https://arxiv.org/html/2410.17875v3
Shi et al. (2024) claims that
“Our approach, named ILA, involves learning a binary mask for the parameter changes in each layer during alignment, as an indicator of layer significance. Experimental results reveal that, despite substantial differences in alignment datasets, the important layers of a model identified by ILA exhibit nearly 90% overlap, highlighting fundamental patterns in LLM alignment.”
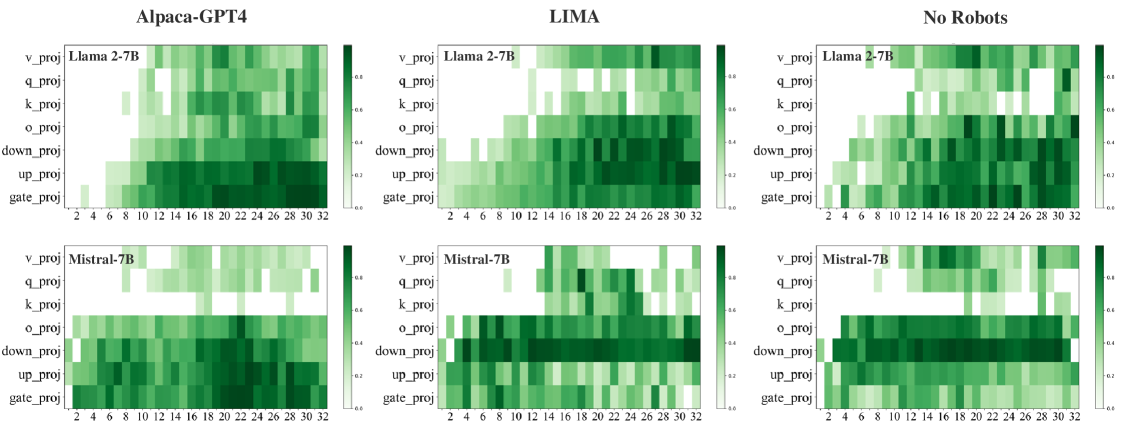
Briefly, alignment through fine-tuning consistently touches the same layers nearly 90% overlap across completely different datasets.
This means two things:
- The rest of the model remains exactly as it was after pretraining.
- I think it matters for security of the model such that a jailbreak does not need to defeat alignment. Just needs to operate in the layers alignment never reached.
I mean that jailbreaks do not need to completely crush model’s internal behavior we need to evade silently (not alerting / triggering) layers while constructing jailbreaks. That is why, the more AI red teamer understands defensive approach, the more they can successfully evade both models whether it is a frontier (state of art) or open weights.
Most patches don’t know where to look. We have to be cautious what or where to patch in also LLM.
Application Patch
When I first encountered the term “application patch”
in the context of AI, I instinctively mapped it to
what I already knew (AppSec). In software, patching has a process. You diagnose a bug, a deprecated dependency, a broken integration.
You reference known resources: OWASP, framework
documentation, prior CVEs. The fix is reproducible
because the problem is locatable.

Application security works the same way. You do not have to reinvent the wheel every time ,so you know where to look.
❝ LLMs break that contract entirely.❞
I mean that no OWASP for neural network layers. Furthermore, no documentation that tells you which attention head fired, which signal crossed which boundary, which layer produced the behavior you are trying to fix.
- You can patch the output.
- You cannot patch the cause.
Not until you can see where the signal lives.
The Identity Gap Between AI Red Teamer & Mechanist
I would like to be honest with you fellows. I think that in every AI red team engagement, I have worked on followed the same pattern:
find the bypass, document the behavior, write the remediation, close the report or sometimes they ask me to explain LLM findings. Plus, every time, somewhere between finding the bypass and writing the remediation, something felt wrong. Not wrong like I made a mistake wrong like I was describing a symptom and calling it a diagnosis. I could break it. I could not explain it. In ethics & moral, it sounds like giving treatment a patient who has heart or teeth related problems and I provide wrong medicine, advice and feels like the patient dead as a result. (it may feels like aggregating the condition ,but ethics matter.).
The fixes I suggested were written by someone who knew
what the output was not what produced it. Prompt hardening, token filtering, guardrails (Llama, Groq): all of them treat the surface. None of them reach the infrastructure level the layer where the decision actually happened. This is the honest limitation of AI red teaming as it stands today. We are exceptionally good at finding where the model fails, and almost completely blind to why. Infrastructure-level solutions such that mechanistic analysis, layer-specific intervention, signal tracing require someone who can take what the red teamer found and locate it inside the model’s actual architecture. That person is the mechanist. The red teamer produces the findings. The mechanist knows where to look. Without both, we are patching in the dark.
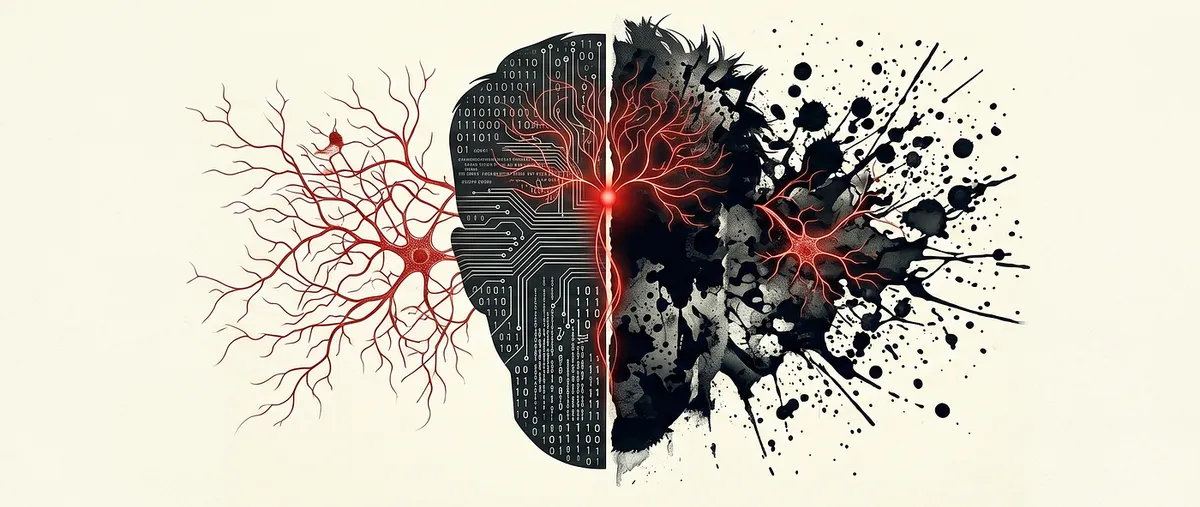
The thumbnail was not accidental. Tyler represents the
red teamer chaotic, destructive, finds everything but
fixes nothing. Edward is the mechanist the suppressed
identity that actually understands the system from the
inside. Jung’s shadow theory applies here too: the
chaos has to exist for the order to emerge.
One without the other is incomplete.